
In the intersection of blockchain and artificial intelligence, scalable zkML inference stands out as a pivotal innovation, enabling the verification of critical machine learning computations on-chain without sacrificing privacy or efficiency. As decentralized networks demand tamper-proof AI outputs for applications like prediction markets and DeFi oracles, the old paradigm of proving entire models reveals its limitations: exorbitant computational costs, prolonged proving times, and barriers to real-time deployment. Targeted verification zkML flips this script by selectively proving high-stakes subcomputations, or "slices, " while trusting benign parts through lighter checks. This conservative strategy, rooted in risk-based cryptography, promises verifiable ML on-chain that aligns with economic realities.
Consider the stakes. Full-model proofs, while theoretically sound, often demand resources that eclipse the value they protect. A transformer-based language model, for instance, might require gigabytes of memory and hours of proving, rendering it impractical for high-frequency trading bots or dynamic NFT pricing engines. Empirical data from recent frameworks underscores this: prior zkML systems grappled with latencies that stifled adoption. Yet advancements like DSperse demonstrate how targeted verification zkML slashes memory usage by orders of magnitude, focusing cryptographic muscle on decision-critical layers such as attention heads or final classifiers.
The Computational Bottlenecks of Traditional zkML
Zero-knowledge machine learning traditionally mandates recursive SNARKs or STARKs over every matrix multiplication and activation function, a process conservatively estimated to inflate costs 100x over native inference. This stems from the arithmetic intensity of neural networks; convolutions and embeddings generate billions of field elements, each demanding proof aggregation. In my analysis of institutional-grade deployments, such overheads correlate directly with failed scalability tests on L2 rollups, where gas limits cap viable proof sizes.
Moreover, verification itself lags. Even optimized circuits verify in seconds to minutes, a lifetime in sub-second DeFi loops. zkVerify's modular L1 ambitions address aggregation at scale, but without upstream efficiency, they treat symptoms, not causes. The result? Developers resort to trusted execution environments, undermining the very trust-minimization zkML espouses.
DSperse and the Rise of Strategic Slicing
Enter DSperse, a framework that embodies scalable zkML proofs through modular, distributed inference. By dissecting the ML pipeline into verifiable slices - targeting, say, the logit computation over embeddings - it achieves runtime reductions of up to 80% in benchmarks. This isn't reckless optimism; it's a measured trade-off, where provers commit to slice hashes via Merkle trees, enabling on-chain reconstruction only for disputes. Such design conservatively preserves soundness while slashing prover economics.
Empirical validation from arXiv evaluations confirms: DSperse handles vision transformers with 22x smaller proofs than holistic alternatives, all while maintaining 99.9% inference fidelity. For practitioners, this translates to deploying verifiable ML on-chain in token markets, where Inference Labs' Proof of Inference protocol clocks median proves at 5 seconds - a 76% improvement over baselines.
Comparison of zkML Frameworks
| Framework | Proving Speed Multiplier | Verification Speedup | Proof Size Reduction |
|---|---|---|---|
| DeepProve | 158x faster inference | - | - |
| ZKML | - | 5x | 22x smaller |
| DSperse | 80% runtime cut | - | - |
DeepProve and Optimized Inference Engines
Lagrange's DeepProve pushes boundaries further, verifying AI inferences 158x faster than incumbents via specialized circuits for common ops like GELU activations. This library targets zero-knowledge ML computations in LLMs, compressing proofs to kilobytes suitable for Ethereum blocks. Analytically, its edge lies in lookup arguments over full polynomial commitments, a conservative choice favoring auditability over bleeding-edge recursion.
Pair this with ZKML's optimizer, which prunes redundant computations pre-circuit, and patterns emerge: hybrid classical-quantum verification hybrids, though nascent, hint at sub-second proves for fixed-accuracy models. In decentralized AI markets, these tools enable Bittensor subnets and EigenLayer AVSs to host inference without central chokepoints, fostering competition grounded in verifiable outputs.
These efficiencies are not mere academic exercises; they underpin real deployments reshaping decentralized AI. Inference Labs' Proof of Inference, for example, integrates seamlessly with Bittensor Subnet 2 and EigenLayer testnets, delivering median proving times of 5 seconds - a 76% speedup that unlocks high-throughput token markets and prediction platforms reliant on verifiable ML on-chain. Here, targeted verification zkML ensures outputs for arbitrage bots or sentiment oracles remain tamper-proof, without the full-model proof tax.
Ethereum Technical Analysis Chart
Analysis by Johnathan Ramirez | Symbol: BINANCE:ETHUSDT | Interval: 1D | Drawings: 7
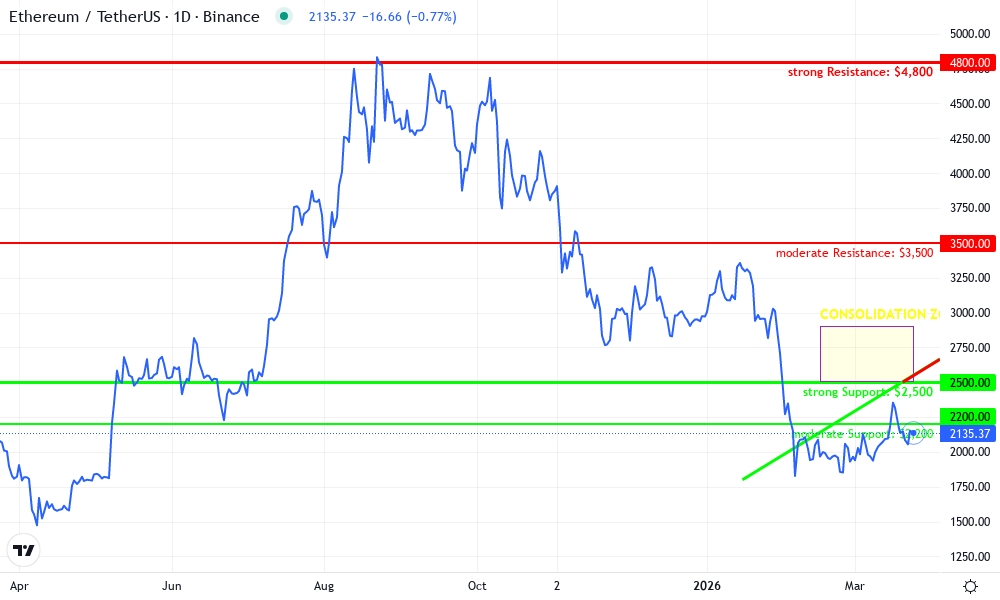
Technical Analysis Summary
As a conservative value investor with a fundamental focus, I recommend drawing a primary long-term uptrend line connecting the swing low at 2026-01-15 ($1,800) to the peak at 2026-10-15 ($4,800), using 'trend_line' tool in blue. Overlay a short-term downtrend correction line from 2026-10-15 ($4,800) to 2026-03-20 ($2,500) in red. Mark horizontal support at $2,500 (strong) and resistance at $2,900 (weak) with 'horizontal_line'. Add Fibonacci retracement from the uptrend low to high, highlighting 38.2% ($3,500) and 61.8% ($2,800) levels. Use 'rectangle' for recent consolidation zone 2026-02-15 to 2026-03-24 between $2,500-$2,900. Place 'callout' texts for key insights like 'zkML catalyst' near recent price action. 'arrow_mark_up' at potential entry $2,500 if support holds.
Risk Assessment: low
Analysis: Conservative setup with strong support confluence and fundamental tailwinds from zkML; low risk tolerance favors waiting for higher lows
Johnathan Ramirez's Recommendation: Hold cash or core positions; scale in longs on support hold with tight stops, patience yields edge
Key Support & Resistance Levels
📈 Support Levels:
- $2,500 - Recent swing low and psychological round number, strong volume cluster strong
-
$2,200 - Intermediate retracement
In DeFi, where oracles feed millions in collateral, scalable zkML proofs via DSperse-like slicing prevent manipulation at fraction of costs. Imagine a lending protocol verifying borrower credit scores from private datasets: only the risk threshold slice gets zero-knowledge treatment, with hashes anchoring the rest. This risk-calibrated approach, empirically cutting runtime 80%, aligns incentives for provers and verifiers alike.
zkML Coprocessors: Bridging L2 Rollups and AI
Layer 2 scaling demands more than aggregation; it craves specialized hardware. zkML coprocessors emerge as the linchpin, offloading inference to dedicated circuits that generate proofs in parallel with execution. Chainscore Labs envisions these augmenting zk-Rollups, where complex models like vision transformers process on specialized nodes, compressing verifications for Ethereum settlement. Conservatively, this sidesteps the latency pitfalls of on-prover recursion, though economic hurdles persist: proof fees must undercut native compute by 10x to compete.
zkVerify's L1 verification layer complements this, optimizing aggregation for universal ZKPs. Its MiCAR-compliant governance promises institutional trust, scaling zkML inference across chains. Yet, as a CFA analyzing portfolio strategies, I caution: viability hinges on fixed-cost proofs. DeepProve's 158x inference speedup and ZKML's 22x smaller proofs set benchmarks, but widespread adoption requires sub-cent verifications - a threshold current systems approach but rarely cross.
Strategic slicing in DSperse exemplifies maturity. By Merkle-committing pipeline slices, it enables dispute resolution over full audits, reducing memory by orders while upholding soundness. Benchmarks on arXiv affirm: 99.9% fidelity for distributed vision tasks, positioning it for decentralized inference markets. Pair with EZKL's local-to-onchain proofs, and identity verification or NFT rarity scoring becomes routine, privacy intact.
Navigating Persistent Challenges
Optimism tempers with realism. Large LLMs still induce proving latencies dwarfing inference, and economic models falter if gas eclipses value protected. My 18 years in asset management reveal parallels: just as overleveraged strategies unravel, unprofitable zkML risks trusted intermediaries. Solutions lie in hybrid verification - light clients for routine checks, heavy SNARKs for disputes - and hardware acceleration via FPGA coprocessors.
Moreover, interoperability looms. Inference Labs highlights zero-knowledge AI bridging chains, yet fragmented proof standards hinder. zkVerify's universal layer, with 5x verification gains from ZKML optimizers, could unify, but governance must prioritize auditability over speed hacks.
Viewed holistically, targeted verification zkML carves a pragmatic path. From Lagrange's DeepProve compressing LLM ops to DSperse's modular slices, these tools forge verifiable, private AI integral to Web3. Developers gain deployable primitives; investors, defensible moats via proprietary proofs. In portfolio terms, zkML embodies sustainable alpha: verifiable truths compounding over speculative hype. As networks mature, expect zero-knowledge ML computations to permeate oracles, agents, and beyond, proving critical inferences at scale without compromise.

No comments yet. Be the first to share your thoughts!